本文共 3701 字,大约阅读时间需要 12 分钟。
每一个业务可以剖析成不同的功能,这些功能都是和数据相关的,所有的功能都离不开数据往往这些数据都需要持久化,这就数据就要进入数据库,要进行增删改查,有了orm这种框架,增删改查变成了对对象的操作。 一般现在都用orm,但是sql语句很重要,所以我们在执行的时候配置成可以看到sql语句。 也可以在modle类对象上,调用查询集的query方法,也可以看到执行的sql语句,最清楚的还是打印日志。一启动其实就链接了一次数据库

用户表的管理一般是增删改查,增就是要提交数据,提交需要给一个url,最终要把这个url映射到某个view函数上,也就是url和view函数建立关系,url的路由。 建立好自己的应用,配置路由应该用多级的方式,每匹配一次把匹配部分去掉,剩下部分匹配下一次的
这两个配合在一起就叫restful的接口设计,这种也叫API设计,除了提供url和method还需要提供数据格式,这里都传了json,什么字段,这三个部分组合起来就叫restful风格的接口设计
 做好路由配置
做好路由配置 
 数据格式,每一个restful的接口都必须要提供url,method,提交的数据。这三样,一样都少不了
数据格式,每一个restful的接口都必须要提供url,method,提交的数据。这三样,一样都少不了  simplejson扔过去什么数据都可以处理,可以理解为增强版的json
simplejson扔过去什么数据都可以处理,可以理解为增强版的json  客户端不能获得python中的异常,django的错误是用response来做的,作成网页端的响应,客户端时通过状态码来判断错对的 200系列都是对的 400系列是客户端访问导致的错误,401输入验证信息,404文件没找到,403权限拒绝 500服务器、
客户端不能获得python中的异常,django的错误是用response来做的,作成网页端的响应,客户端时通过状态码来判断错对的 200系列都是对的 400系列是客户端访问导致的错误,401输入验证信息,404文件没找到,403权限拒绝 500服务器、  错误写在这里,可以想办法在前端展示,比如用户名密码错误,或者用户名被禁用,也可以用jsonresponse,jsonresponse底层调用的也是httpresponse,可以把原因写在字典中,只不过出错要手动改状态码,比如status:400
错误写在这里,可以想办法在前端展示,比如用户名密码错误,或者用户名被禁用,也可以用jsonresponse,jsonresponse底层调用的也是httpresponse,可以把原因写在字典中,只不过出错要手动改状态码,比如status:400 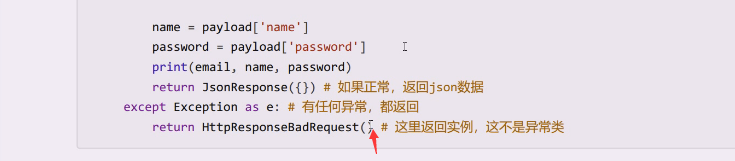
 要么把中间件关闭,测试的时候用的,上线就不要关了,建议打开
要么把中间件关闭,测试的时候用的,上线就不要关了,建议打开 
 用户提交就需要form表单,我们就可以在表达里加csrf_token,生成一个hidden的input,这种往往放在模版页
用户提交就需要form表单,我们就可以在表达里加csrf_token,生成一个hidden的input,这种往往放在模版页 现在如果是前后端分离,用ajax,在请求的header里加x-csrftokenm,这些信息怎么来,其实很简单,可以访问特定页面就返回这个值即可,只要response值即可
现在如果是前后端分离,用ajax,在请求的header里加x-csrftokenm,这些信息怎么来,其实很简单,可以访问特定页面就返回这个值即可,只要response值即可 
得到了第一版本代码

 浏览器端的代码写的再好,也避免不了用户躲避验证,绕开网页,比如直接用postman直接提交,也是没办法的,服务器端也需要验证。 还有csrf,也可以先用浏览器把值保存下来,用postman把这个头带上发给你,还是避免不了。 所以在后端服务器代码也要做验证,只要是客户端发来的数据,一个都不能信
浏览器端的代码写的再好,也避免不了用户躲避验证,绕开网页,比如直接用postman直接提交,也是没办法的,服务器端也需要验证。 还有csrf,也可以先用浏览器把值保存下来,用postman把这个头带上发给你,还是避免不了。 所以在后端服务器代码也要做验证,只要是客户端发来的数据,一个都不能信  这里是查一下email存在不存在,objects实际上是一个管理器
这里是查一下email存在不存在,objects实际上是一个管理器  调用save里面会自动commit,一般注册成功会返回注册成功,但是不跳转,因为你还需要登录一次,甚至要去邮箱激活一把,才能允许登录,一般注册成功不会做什么事情,只会返回一个id,有id就告诉它注册成功,这个就是一种状态,习惯返回一个id
调用save里面会自动commit,一般注册成功会返回注册成功,但是不跳转,因为你还需要登录一次,甚至要去邮箱激活一把,才能允许登录,一般注册成功不会做什么事情,只会返回一个id,有id就告诉它注册成功,这个就是一种状态,习惯返回一个id 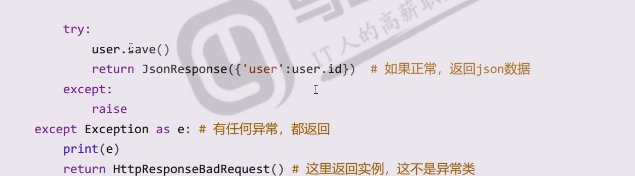
 异常要返回,不能掉raise,因为都是response类的实例,
异常要返回,不能掉raise,因为都是response类的实例, 

 这个是一个内建对象,只要构建成model类的子类,就会给你内部添加这个,这个称为管理器,可以自定义,但是一般不自己定义,不定义会提供一个objects的东西,称为管理器,管理器的类型
这个是一个内建对象,只要构建成model类的子类,就会给你内部添加这个,这个称为管理器,可以自定义,但是一般不自己定义,不定义会提供一个objects的东西,称为管理器,管理器的类型 
管理器是用来跟数据库打交道的,使用它就可以调用相应的操作,主要还是来做数据库查询的事情的,,增加save,修改也是save,只要你在写查询的时候,基本上就是前面user一个类.objects,提供了一些查询接口,django应用的每个接口模型里面可以定义多个管理器,至少有一个,没有就无法查询了

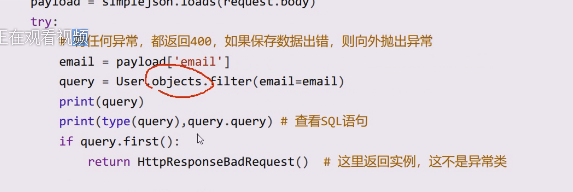 **数据的检验是放在save和update上 ,不调用save这些方法的时候,发现其实里面有一些数据是不合适的,实际上是不报错的 **
**数据的检验是放在save和update上 ,不调用save这些方法的时候,发现其实里面有一些数据是不合适的,实际上是不报错的 ** 

惰性求值不会主动去查询,直到在迭代的时候(跟生成器一样,迭代了,生成器只能去生成数据),序列化把里面数据拿出来,数据库会把你符合的数据都发过来,数据很大想办法limit,序列化的时候也需要数据,所以也需要提前把结果集合返回来。
结果集本身是一个缓存,本身查询来的数据会放在客户端(数据库的客户端,也就是django写的程序) 这个缓存其实可以用,每个查询集都包含一个缓存,来最小化对数据库的访问,因为查询数据库是一件非常耗时的工作。首次查询是要查的,但是后面如果可以用缓存数据就用缓存数据
这个缓存其实可以用,每个查询集都包含一个缓存,来最小化对数据库的访问,因为查询数据库是一件非常耗时的工作。首次查询是要查的,但是后面如果可以用缓存数据就用缓存数据 
 看一个例子,到user的视图函数views,先这么写,注意这是. ,记得在生产的时候要limit*
看一个例子,到user的视图函数views,先这么写,注意这是. ,记得在生产的时候要limit* 
配置一下url
 现在过来的是空包
现在过来的是空包  之前在sqlalchemy,all是消费者方法,只要调用就查了,这里还是没查,所以这里不能完全跟sqlalchemy对应起来
之前在sqlalchemy,all是消费者方法,只要调用就查了,这里还是没查,所以这里不能完全跟sqlalchemy对应起来  从users里遍历所有东西,并且立即用列表封起来
从users里遍历所有东西,并且立即用列表封起来 
 走一把现在就查了
走一把现在就查了  这样做试试查几遍
这样做试试查几遍 
 只查了一遍
只查了一遍  因为这是一个结果集,也就是遍历几遍结果集而已,所以就查一次
因为这是一个结果集,也就是遍历几遍结果集而已,所以就查一次 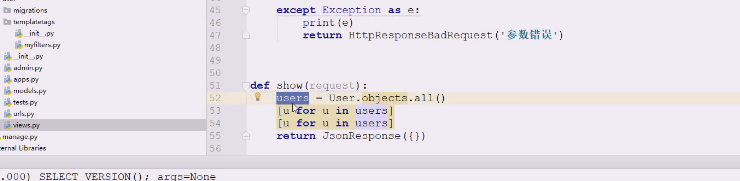 刚才是用同一对象遍历,结果集可以反复用。试试这样需要几遍
刚才是用同一对象遍历,结果集可以反复用。试试这样需要几遍 
 查询了两次,要操作的话尽量不要调用all方法两次
查询了两次,要操作的话尽量不要调用all方法两次 还是建议这么用
还是建议这么用 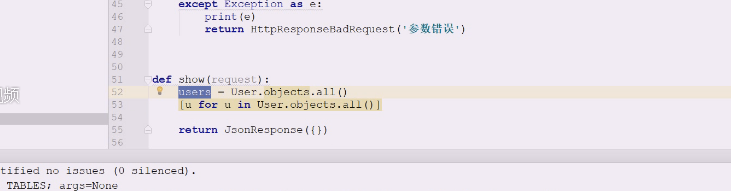
 数据太大,想要切片
数据太大,想要切片 



下一个
 现在有三条数据,但是这个数据没有样子
现在有三条数据,但是这个数据没有样子  加显示头,这两个是同样的函数
加显示头,这两个是同样的函数  这里就受我们str的影响
这里就受我们str的影响 操作索引,都是从0开始
操作索引,都是从0开始  看看打印出来谁,试试切片
看看打印出来谁,试试切片 

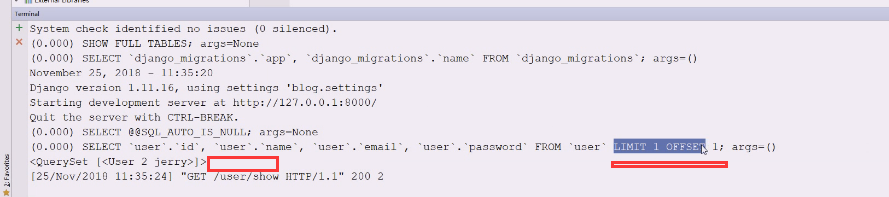 这么写看看怎么给你解决的sql语句
这么写看看怎么给你解决的sql语句 

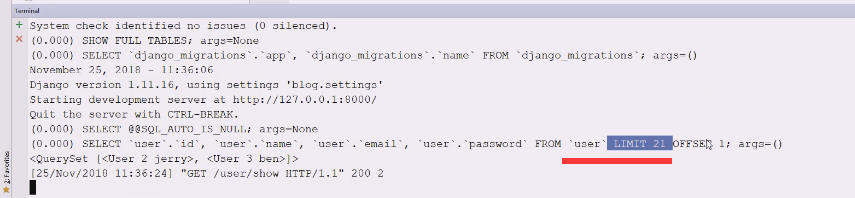


 按照道理应该是limit2
按照道理应该是limit2 
 limit2,offset可以不写
limit2,offset可以不写 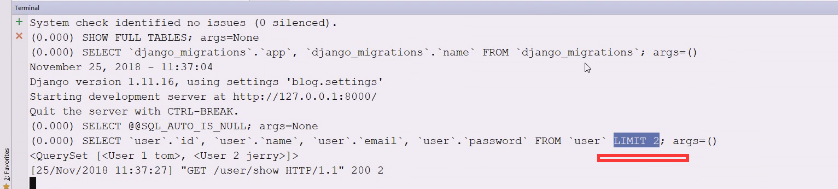 现在不要这个,相当于没有用查询
现在不要这个,相当于没有用查询 
 多发送几次请求
多发送几次请求  并没有sql语句
并没有sql语句 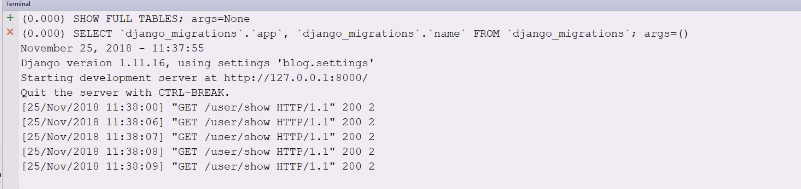 按照以前的理解是切片立即执行,但是这里是不要数据就不查
按照以前的理解是切片立即执行,但是这里是不要数据就不查

 其实是准备好了,但是我们没有真正调用数据就没有真正去查询
其实是准备好了,但是我们没有真正调用数据就没有真正去查询 从第11开始取10个人
从第11开始取10个人 这个是谁到谁,并不是偏移多少个
 切片足够懒,不用不查
切片足够懒,不用不查 

 在其他叫消费者方法,在这里叫过滤器
在其他叫消费者方法,在这里叫过滤器 
 filter写条件
filter写条件  这个条件就需要排除出去
这个条件就需要排除出去 

返回一个对象字典列表,列表的元素是字典,字典内是字段和值 的键值对


 object上直接这么写
object上直接这么写 
 现在就可以了
现在就可以了 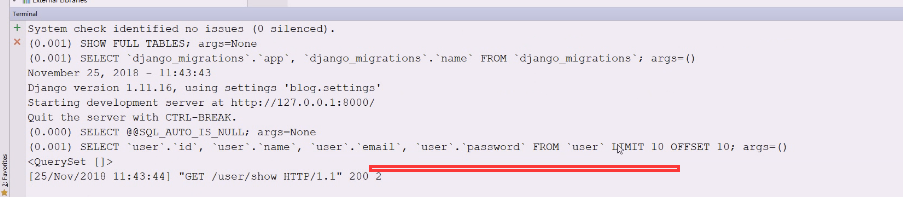

 前面是all查的,后面是values显示结果集,变成字典式了
前面是all查的,后面是values显示结果集,变成字典式了  现在写查询的时候最重要的是写filter
现在写查询的时候最重要的是写filter  两个可以链接在一起写
两个可以链接在一起写  只要是主键就用pk,pk会代替这个主键
只要是主键就用pk,pk会代替这个主键  、
、


 pk=1and name=tom
pk=1and name=tom 

 真实的字段名叫id
真实的字段名叫id 
 没有什么变化,这个pk就是指代主键的
没有什么变化,这个pk就是指代主键的  提供单值的方法,查询出来提供一个值
提供单值的方法,查询出来提供一个值 
 查询总条目数
查询总条目数  要么有数据,拿第一条,等于强制limit 1,没有数据返回none,不抛出异常
要么有数据,拿第一条,等于强制limit 1,没有数据返回none,不抛出异常  返回最后一个,没有数据返回none,不抛出异常
返回最后一个,没有数据返回none,不抛出异常  判断查询集是否有数据
判断查询集是否有数据  可以理解为只要一条数据的filter
可以理解为只要一条数据的filter 

 现在查一个没有的
现在查一个没有的 
直接抛出异常,get方法只能是一条,否则抛出异常  试试count方法
试试count方法 




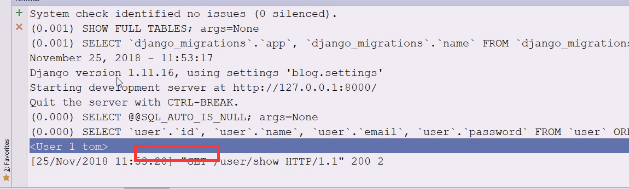

 应该用like试试
应该用like试试  可以进行这样的查询
可以进行这样的查询  id如果是主键可以用pk代替
id如果是主键可以用pk代替  有就回来,没有就是none
有就回来,没有就是none 
刚才只要查询条件不写等于=就出问题,因为大于小于不让写,这时候就需要用到查询表达式



 小于等于怎么写,加个e试试
小于等于怎么写,加个e试试 
 小于等于3来 了
小于等于3来 了 

 这个就是lookup表达式
这个就是lookup表达式 
 所以字段名不能这么写,因为lookup表达式就不能用了/
所以字段名不能这么写,因为lookup表达式就不能用了/
转载地址:http://kozgn.baihongyu.com/